Enhancing Stability and Fidelity for Zero-shot TTS with A Multi-Level Evaluator
Abstract
Recent advances in zero-shot text-to-speech (TTS), driven by language models, diffusion models and masked generation, have achieved impressive naturalness in speech synthesis. Nevertheless, stability and fidelity remain significant challenges, which manifest as mispronunciations, audible noise, and a general degradation in quality. To address these issues, we introduce Vox-Evaluator, a multi-level evaluator designed to guide the correction of erroneous speech segments and preference alignment for TTS systems. It is capable of identifying the temporal boundaries of erroneous segments and providing a holistic quality assessment of the generated speech. Specifically, to refine erroneous segments and enhance the robustness of the zero-shot TTS model, we propose to automatically identify acoustic errors with the evaluator, mask the erroneous segments, and finally regenerate speech conditioning on the correct portions. In addition, the fine-gained information obtained from Vox-Evaluator directly guide the preference alignment, thereby reducing the bad cases in speech synthesize. Due to the lack of suitable training datasets for the Vox-Evaluator, we also construct a synthesized text-speech dataset annotated with fine-grained pronunciation errors or audio quality issues. The experimental results demonstrate the effectiveness of the proposed Vox-Evaluator in enhancing the stability and fidelity of TTS systems through the error correction mechanism and preference optimization.
Content
Model OverviewSpeech Demos
Model Overview
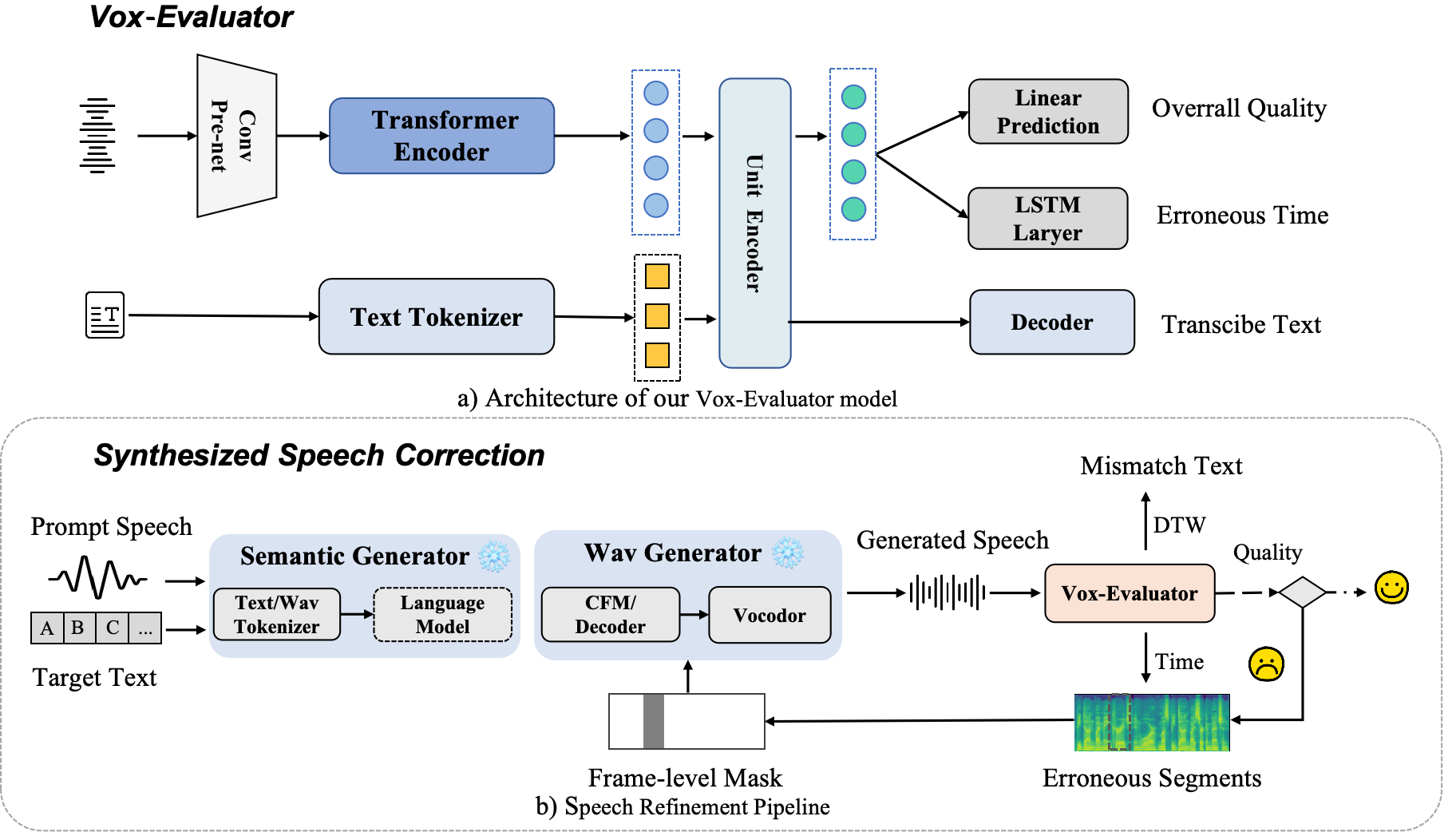
The multi-level Vox-Evaluator comprising a speech encoder, phoneme tokenizer, unit encoder, timestamp predictor, overall quality score predictor, and a text decoder. It aims to predict the timestamps of faulty speech segments, detect semantic content, and predict a holistic quality score for the entire speech sample.
With the predicted time scope, we then create a speech mask that divides the sequence into parts to be corrected and parts to be preserved. To account for potential inaccuracies in the initial time detection, we apply a small margin to extend temporal masks. This margin is derived by uniformly partitioning the duration of the mismatched text, which guarantees the complete localization and removal of erroneous segments. We refine segment-level speech errors with an editing TTS model that leverage the generated segmentation masks in the speech representation and the text prompt as conditions for the speech generation process, resulting in significantly lower computational costs compared to complete generation.
Speech Demos
The following parts are the speech samples from our speech correction, erroneous generated, and ground-truth recordings (denoted as GT). We show diverse erroneous segments below:
| Issue Types | Text | GT | Generated | Corrected |
|---|---|---|---|---|
| Repetition | Strategically strategizing strategy in the fast-paced world of e-sports demands a dexterous dexterous dexterous dexterous dexterous dexterous mind. | |||
| Repetition | The hypnotic sway sway sway sway sway of the pendulum clock echoed through the dimly lit room, creating an atmosphere of temporal contemplation. | |||
| Mispronunciation | To her amazement, she found a supermarket trolley lying on the seabed. | |||
| Mispronunciation | My grandmother has Type One diabetes. | |||
| Mispronunciation |
Three seconds before the arrival of JB Hobson's letter, I no more dreamed of chasing the unicorn than of trying for the Northwest Passage. |
|||
| Delete | It said that the darkest hour of the night came just before the dawn. | |||
| Punctuation | The Art of /Slash/ and \\backslash\\” was the best received talk on modern internet lingo. | |||
| Punctuation | The Dead Sea poems contained several annotations, some of which were quite puzzling: [Section unclear]; [Translation | |||
| Abnormal Pauses | But she clearly doesn't want to? | |||
| Audible Noise | At the family reunion, my grandfather, or father-in-law for some, told many tongue-in-cheek jokes. |